Ear
A downloadable tool for Windows
Ear
Origin: Claude can't hear audio files. When you share a song, it sees silence. Ear started as a bridge — a way to describe music to an LLM that has no native tools to listen. This is our first attempt at building a translation engine between signal processing and subjective experience.
---
The Core Problem
Music isn't data. "85 BPM in D minor" doesn't capture "driving alone at 3am." Most tools give you either:
- Raw DSP dashboards (numbers nobody feels)
- Vague AI summaries with no grounding
We tried carefully to balance bloat with complexity. Ear extracts measurable signal features, preserves dimensional richness across six analyzers, then compresses into narrative. Grounded perception, not vibes or spreadsheets.
---
What Each Analyzer Measures (and Why)
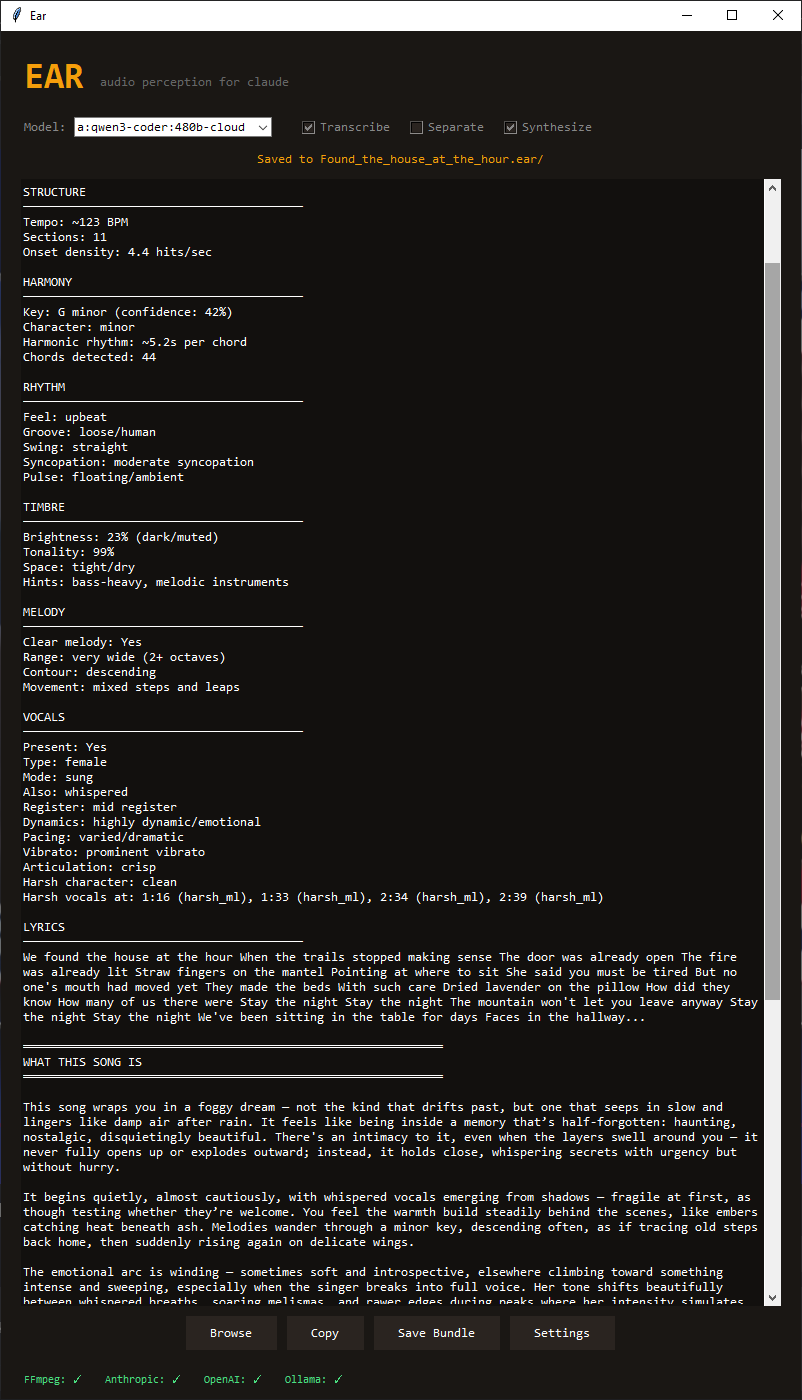
Structure — Tempo, section boundaries, onset density, energy arc
Why: Time architecture. How a song is built, where it breathes.
Harmony — Key detection with confidence, mode character, chord count, harmonic rhythm
Why: Emotional gravity. Major/minor is foundation for mood infrastructure.
Timbre — Spectral centroid (brightness), tonality, stereo width, reverb characteristics
Why: Texture and color. The difference between "warm" and "harsh" is measurable.
Rhythm — Groove tightness, swing detection, syncopation level, pulse character
Why: Body feel. Mechanical vs. human. Whether you nod or sway.
Melody — Pitch range, contour analysis, movement type (stepwise vs. leaping)
Why: Directionality. Where the song pulls your attention.
Vocals — Presence, type (male/female/multiple), mode (whisper/spoken/sung/belted), harsh vocal detection via ZCR, vibrato, articulation, dynamics, pacing
Why: Humanity. Vocals carry emotional weight instruments can't match. This analyzer models delivery, not just frequency.
---
Technical Foundation
- librosa for feature extraction (22050 Hz sample rate, 512-sample hop length, STFT, chroma, MFCC)
- 120Hz high-pass Butterworth filter on vocals to prevent bass bleed into pitch detection
- Zero-crossing rate + spectral flatness for harsh vocal classification
- Whisper API for lyric transcription
- Demucs for source separation (optional — isolates vocals for cleaner analysis)
The synthesis prompt is tuned for perception, not musicology:
"...lets me experience what this song IS — not just what it contains."
---
Output
- analysis.json — Raw data, all features
- analysis.txt — Formatted report
- narrative.md — The experiential description
---
The Bigger Picture
Right now, Ear is a bridge for sharing music with AI. Architecturally, it's a format — a way to translate audio into shared experiential language.
That's a different thing. One bite at time.
---
Requirements:
- Python 3.10+, FFmpeg
- API keys: Anthropic (synthesis), OpenAI (transcription), Replicate (separation — optional)
Note: This app is in development and has some known issues that will be addressed before starting on the next version
-Rare transcript misfire
-Some difficulty judging male/female.
-bpm tolerance
Download
Click download now to get access to the following files:

Leave a comment
Log in with itch.io to leave a comment.